
Un post de síntesis, para esta serie sobre el análisis de código PL / SQL con SonarQube.
Después de configurar nuestro análisis con Jenkins, lo lanzamos y encontramos 17 defectos bloqueantes (Blockers), pero ninguna falta crítica (Criticals)
con el perfil de calidad de SonarQube. De hecho, las 5 reglas Criticals
eran desactivadas y también algunas otras normas de diferentes
criticidades: 58 en un total de 132.
Así que hemos creado nuestro propio Quality Profile
para activar todas estas reglas, ejecutado de nuevo un análisis y
examinado las reglas que tenemos en las diferentes categorías Blockers,
Criticals y Majors.
El objetivo de este trabajo es para mí construir una demo con código
PL/SQL para presentar a un cliente los beneficios que se pueden
conseguir con SonarQube. Por esta razón, yo decidí subir en Criticals o
incluso en Blockers algunas reglas sobre la robustez, la seguridad y el
rendimiento, y reducir las normas de legibilidad o de portabilidad del
código. Sólo porque quiero destacar las violaciónes que pueden impactar
al usuario final:
- una aplicación que se detiene de repente,
- una transacción que no se ha completado, con una posible corrupción de datos,
- un error en un algoritmo que lleva a un error de lógica o de cálculo,
- un rendimiento menor,
- etc.
¿A que parece ahora mi dashboard SonarQube? ¿Cuáles son las
informaciones útiles que puedo enseñar en una presentación? Aunque el
cuadro de mando SonarQube está muy bien organizado, es fácil no saber
por dónde empezar.
No voy a explicar aquí cómo hacer una demo, y mucho menos cómo voy a
construir una auditoría de la calidad del código. Se necesitaría más de
un post, y probablemente será el tema de una otra serie en el futuro.
Pero en modo de síntesis de los articulos anteriores de esta serie, voy a
presentar lo que hago para cualificar una nueva aplicación.
El tamaño
Cuando encuentras a una persona, la primera cosa que se puede observar, es su talla. ¿Es grande, media, pequeña?
 Un
primero widget me permite ver que tenemos aquí 16 ficheros o programas
de base de datos, que contienen 1 569 ‘functions’ (objetos, componentes
de tipo procedimiento, función, trigger, etc.) representando 28 116
instrucciones (statements).
Un
primero widget me permite ver que tenemos aquí 16 ficheros o programas
de base de datos, que contienen 1 569 ‘functions’ (objetos, componentes
de tipo procedimiento, función, trigger, etc.) representando 28 116
instrucciones (statements).
Esta aplicación cuento con un poco más de 95 KLoc (milles de Lines of
Code) en un total de 147 KLoc : la diferencia está en las líneas de
comentario (o las líneas blancas, o de código en comentario).
Con el widget ‘Custom Measures’, me he customizado mi propio ‘panel’ para ver todas las informaciones de tamaño y de comentario.
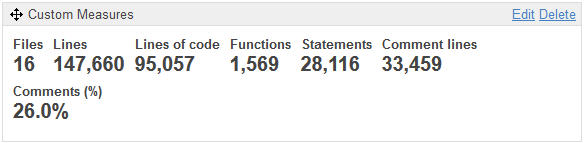
¿Qué podemos deducir ?
Tenemos una aplicación de tamaño entre medo y grande para esta
tecnología PL/SQL, con un porcentage de más del 25%, pues correcto (sin
llevar a augurar de su calidad).
El número medio de líneas de código por objeto (Funciones ) es
inferior a 100: de nuevo, es acceptable. Contamos un promedio de 18
instrucciones (Statements) por objeto, así que de nuevo no es enorme.
Basandonos en estas cifras, se podría pensar que una corrección o un cambio en estos componentes no sería una carga excesiva.
Excepto que todo este código se encuentra en tan sólo 16 archivos, es
decir, 16 scripts o programas de base de datos. La granularidad de cada
componente puede ser correcta, pero un promedio de 6 000 líneas de
código por archivo es enorme, y podemos imaginar que esto va a impactar
en la capacidad de mantenimiento.
Añadir o editar código en un componente PL/SQL de 100 líneas es
relativamente fácil. Pero cuando tienes que buscar estas 100 líneas o el
código de todos los demás componentes que se verán afectados por este
cambio, en un programa de 6 000 líneas de código, vas a necesitar tiempo
y el riesgo de introducir un error durante esta corrección o esta
evolución también será alto.
Por lo tanto, el siguiente paso en el descubrimiento y la evaluación
de la calidad de esta aplicación consiste en comprobar la granularidad
de sus componentes.
Granularidad de los componentes
En esto, un nuevo widget introducido en la versión 4.1 de SonarQube
representa un gran valor. El Project File Bublle Chart muestra la
distribución de los diferentes archivos en dos ejes: el número de líneas
de Loc en el eje horizontal X, y el número de violaciónes de las buenas
prácticas de programación en el eje vertical Y. Tengas en cuenta que he
elegido una escala logarítmica para el segundo eje Y. El tamaño de cada
burbuja representa la deuda técnica calculada en número de días para
cada componente. Todo esto es configurable .

Apuntando a una burbuja, podemos ver sus características. A la
izquierda, el program ‘CreatePackage1.sql’ contiene 6 119 líneas de
código, más de 4 000 defectos y una deuda técnica de 228 días.
El script ‘Create_Tables.sql’ en el medio del gráfico, contiene 2,5
veces más de líneas de código (16 810 Loc), pero sólo 400 defectos y
entonces una deuda técnica muy baja (8 días).
Y en la parte superior derecha de este gráfico, nos encontramos con
el archivo ‘CreatePackageBody.sql’ con casi 58 500 líneas de código,
cerca de 20.000 defectos y más de 1 400 días de deuda técnica.
Se puede pensar que el equipo del proyecto responsable de esta
aplicación es completamente irresponsable por dejar crecer este programa
hasta este punto. De hecho, en absoluto. Tenemos aquí un conjunto de
scripts y programas de base de datos para una aplicación
cliente-servidor muy antigua (más de 20 años de edad ), con los
tratamientos de lógica de aplicación deportados en la base de datos. Era
eso o codificar estos tratamientos en las pantallas, con los lenguajes
de aquella época, lo que no era del todo recomendable.
Pero ¿por qué implementar toda la lógica de negocio en un único
archivo? Otra solución sería la de distribuir todos estos tratamientos
en diferentes programas, pero eso complica la gestión de todos los
enlaces entre ellos, y en diferentes versiones. En estos tiempos, no
existían herramientas de gestión de configuración (SCM). También es más
complicado reconstruir la base de datos con varios programas que se
deben ejecutar en un orden estricto, con las diferentes versiones
correctas. Era frecuente ver el equipo de proyecto trabajando durantes
semanas en cambiar los procedimientos, para descubrir que no se podia
lanzar el programa A porque se necesitaba la presencia en la base de
datos de un componente del programa B, y este no se podía tampoco
ejecutar sin que existe ya un componente del programa A. Doble enlace
mortal.
Una revisión rapida de los otros archivos nos permite verificar que
estos programas son responsables de la creación de vistas (Views),
triggers, etc. y con pocas líneas de código y entonces pocos defectos.
Por ejemplo, el script de creación de tablas presenta muy pocas
violaciónes en un alto número de Loc porque no hay tratamientos.
Las medidas de tamaño parecían indicar un código no demasiado
complejo hasta que el Bubble Chart nos indica todo lo contrario: más del
60 % del código de la aplicación se encuentra en un componente
monstruoso con todos los tratamientos de lógica de aplicación.
Es muy probable que los costes de mantenimiento de esta aplicación se verán afectados por eso.
¿A que parece ahora nuestro dashboard SonarQube?
Hemos examinado en el post anterior las métricas de tamaño y no dimos cuenta que el número medio de líneas de código por objeto (procedimiento, función, trigger, etc. ) no estaba mal.
Con el nuevo widget File Bubble Chart, descubrimos más de 58.000
líneas de código en un único archivo ‘CreatePackageBody.sql’, con toda
la lógica de negocio implementada en la base de datos, lo que sin duda
resultará en un coste de mantenimiento alto para esta aplicación.
Complejidad y duplicación
Complejidad
 Si echamos un ojos a la Complejidad Ciclomática (CC), encontramos
resultados similares: la complejidad promedio por objeto es
relativamente baja con 6.9 puntos de CC, y un máximo de 12 puntos. Pero
la complejidad por archivo supera los 600 puntos, y tenemos un total de
poco más de 10.000 puntos de CC en toda la aplicación, lo cual no es muy
alto.
Si echamos un ojos a la Complejidad Ciclomática (CC), encontramos
resultados similares: la complejidad promedio por objeto es
relativamente baja con 6.9 puntos de CC, y un máximo de 12 puntos. Pero
la complejidad por archivo supera los 600 puntos, y tenemos un total de
poco más de 10.000 puntos de CC en toda la aplicación, lo cual no es muy
alto.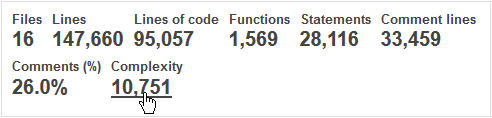
El esfuerzo de test para esta aplicación no es muy importante.
Recordemos que la Complejidad Ciclomática es una medida de la cantidad
de diferentes ‘caminos’ en una aplicación. Lo ideal sería hacer pruebas
de todos los caminos, por lo que la CC nos da una idea del esfuerzo de
pruebas.
Se considera que a partir de 20 000 puntos para una aplicación, es
necesario realizar un control de calidad (QA) específico, definir y
realizar casos de test y si es posible, automatizar las pruebas. En
nuestro caso, podemos dejar el equipo del proyecto realizar estas
pruebas de forma interna.
Pero como se puede ver con el siguiente Treemap que he configurado para mostrar la Complejidad Ciclomática …
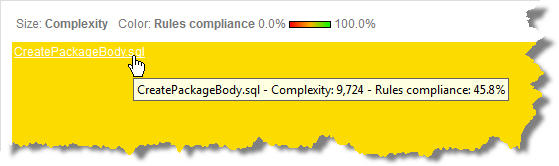
Nuestro fichero ‘CreatePackageBody.sql’ representa 90% de la
complejidad y por lo tanto, de la lógica de la aplicación. Así que una
vez más, tenemos cifras correctas a nivel de aplicación excepto que la
casi toda la aplicación se encuentra en un solo archivo.
Duplicaciones
 Después
de la complejidad, voy a interesarme en el nivel de duplicación,
bastante alto. Sin sorpresa, el mismo archivo monstruoso que implementa
la lógica de negocio se encuentra de nuevo en primera fila.
Después
de la complejidad, voy a interesarme en el nivel de duplicación,
bastante alto. Sin sorpresa, el mismo archivo monstruoso que implementa
la lógica de negocio se encuentra de nuevo en primera fila.
Sin embargo, nos encontramos con un gran número de Copiado/Pegado en
los otros archivos, especialmente en el fichero ‘Create_tables.sql’.
Este script se encarga de crear las tablas de la base de datos, lo que
significa que se duplican muchas estructuras de datos.
Eso puede indicar que el modelo de datos no está optimizado. Esto
sucede por una aplicación de tipo Legacy, porque es más fácil agregar
nuevas tablas que hacer evolucionar las existentes. Pero más tablas
significa más enlaces, y por consiguiente un rendimiento inferior y más
complejidad para mantener estas estructuras de datos.
En el contexto de una auditoría real de la calidad de esta
aplicación, yo tomaría el tiempo para investigar este fichero y
investigar esta hipótesis y encontrar algunos ejemplos que pueden apoyar
un refactoring del ‘data model’.
Por ejemplo, hay 687 sentencias ‘CREATE TABLE’ en este archivo, y
entonces 687 tablas en total (sin contar las ‘views’). 8 963 líneas
duplicadas en este script significa un promedio de 13 líneas, pues 13
campos similares en cada tabla. Tiene sentido tener algunos campos
‘claves’ para llevar a cabo los ‘join’, pero tal vez no tantos.
Componentes con riesgo
Después de ver los indicadores cuantitativos, ya tenemos una gran
cantidad de información con respecto a esta aplicación, sin duda más que
por lo general conocen los responsables del proyecto, por no hablar de
los stakeholders y los responsables de TI.
La segunda parte de una evaluación de la calidad consiste en
identificar las principales amenazas, y esto requiere buscar los
componentes de mayor riesgo. Hemos visto en los artículos anteriores:
- 16 bloqueadores en la regla ‘Use IS NULL and IS NOT NULL instead of direct NULL comparisons’, y además duplicados varias veces: es probable que alguien en el equipo necesita refescarse la memoria acerca de esta regla.
- 2 ‘Calling COMMIT or ROLLBACK from within a trigger will lead to an ORA-04092 exception’. Y 1 ‘Do not declare a variable more than once in a given scope (PLS-00371)’: errores por falta de atención probablemente, la perfección no es de este mundo. En todos los casos, a corregir urgentamente por el riesgo que estos defectos representan para los usuarios.
He promocionado unas reglas règles Major a la categoria Critical, y entonces ahora tenemos:
- 320 ‘Sensitive SYS owned functions should not be used’, incluyendo 270 en nuestro fiechero ‘CreatePackageBody.sql’: esto es el problema con el Copy / Paste, se duplican defectos críticos para la seguridad de las aplicaciones.
- Una serie de nuevos defectos para las reglas principales que hemos puesto en esta categoría Critical.

La mayoría de estas reglas impactan el rendimiento o la fiabilidad de
la aplicación, y por lo tanto representan un riesgo para el usuario
final.
Entonces se recomienda corregir estos componentes riesgosos, sobre
todo si la satisfacción de los usuarios es un objetivo importante para
nuestro departamento de TI.
La evaluación de la calidad de una aplicación no es sólo el análisis
de código: eso, cualquiera puede hacerlo. El trabajo del consultor se
basa en las siguientes preguntas: qué, por qué, cómo, cuánto.
- Qué: analizar los resultados. El tamaño, la complejidad y la duplicación de código, esto es lo que hemos visto en los articulos anteriores. Se examinan las cifras globales, el promedio, así como las tendencias en el tiempo, si hay varias versiones. Luego nos fijamos en las principales violaciónes de buenas prácticas, principalmente los Blockers y Criticals.
- ¿Por qué estos resultados?: investigamos las causas de los datos en el cuadro de mando SonarQube, el origen de los resultados encontrados.
- ¿Cómo remediar?: proponer un plan de acción. De hecho, varias propuestas de acción. Más adelante veremos que pensamos en diferentes planes en el corto, mediano y largo plazo.
- ¿Cuánto cuesta?: evaluar el coste de cada plan.
Por ejemplo:
- Qué: encontramos un defecto crítico para la seguridad.
- Por qué: es probable que al menos una persona en el equipo de proyecto no conoce esta regla. O esta buena práctica se conoce, pero siempre es posible un error por falta de atención.
- Cómo: la remediación puede consistir en una simple corrección del defecto en el código o una capacitación en estas buenas prácticas.
- Cómo : aquí es donde el plugin SQALE será útil.
No voy a explicar en detalle el método SQUALE y el plugin SQALE de
SonarQube. Tal vez tendremos la oportunidad de hacerlo en un futuro
post, pero ya hay suficiente información sobre el tema. Le aconsejo ver
estos enlaces:
Para nuestros cálculos, consideramos que el equipo del proyecto para
mantener este código SQL se compone de 3 personas. En general , una
aplicación de tipo Legacy no cambia con mucha frecuencia, por lo que
consideramos que el equipo produce cuatro versiones por año.
Recordemos que un año-hombre es igual a 52 semanas, menos las vacaciones
y otras fiestas (u otro tipo de ausencias. por enfermedad por exjempo),
o 45 semanas o 225 días (en Francia). Esta cifra puede variar entre
país, pero no tanto.
La deuda técnica en PL/SQL
Plan de corto plazo – Quitar las amenazas
El más importante y prioritario es eliminar todo lo que constituye
una amenaza para el usuario final, lo más rápido y lo más ante posible.
Este es el nivel mínimo, esencial, en corto plazo entonces.
Hemos centrado nuestro Perfil de Calidad en violaciónes de seguridad,
robustez y rendimiento, que tienen impacto con el usuario. Obviamente
los bloqueadores y defectos criticos son las amenazas más graves.
El plugin SQALE nos permite comprobar el coste de remediación para ellos: unos 113 días.

El plan a corto plazo será un proyecto de refactorización de 6
meses/hombre, o sea dos meses para las 3 personas de nuestro equipo de
proyecto.
Cuándo: tan pronto como sea posible, para la próxima versión dentro
de 3 meses. Es perfectamente aceptable presentar a los stakeholders el
plan de posponer las evoluciones no esenciales en la versión siguiente,
para que el equipo de proyecto pueda realizar los dos meses de
refactorización primero, y luego trabajar el último mes en las mayores
funcionalidades. Si son demasiadas, es posible jugar con el tiempo,
desplazando la próxima versión en 4 meses. O hacer una versión
‘refactorizada’ en 2 meses, y la siguiente en 4 meses.
Beneficios: una aplicación más segura, más robusta y eficiente,
gracias a la eliminación de las amenazas más urgentes y más graves.
Plan de mediano plazo – Alinear TI con los objetivos de deuda técnicas
Nunca debemos olvidar que la estrategia de TI, y entonces la gestión
del portafolio de aplicaciones, siempre se alinea con la estrategia de
negocio. Un mercado puede ser:
- Maduro, con una estrategia de preservación de la cuota de mercado y de los márgenes financieros, por lo que el cumplimiento de los presupuestos y los costes serán un objetivo esencial de la estrategia de TI. Para el equipo del proyecto, esto significa centrarse en la mantenibilidad y la capacidad de evolución de la aplicación. No deje que se deriva la deuda técnica para estos dos factores.
- Nuevo, con una estrategia de ganancias de cuotas de mercado, time-to-market de las aplicaciones, robustez y rendimiemto: esta es la orientación que hemos dado a nuestro perfil de calidad y el análisis de la calidad de la aplicación.
Por consiguiente, nuestro plan de mediano plazo tendrá como objetivo
corregir todos los defectos que afectan a la seguridad, el rendimiento y
la fiabilidad, y no sólo a los Blockers y Criticals. La pirámide SQALE
nos permite calcular el coste de este plan de mediano plazo:
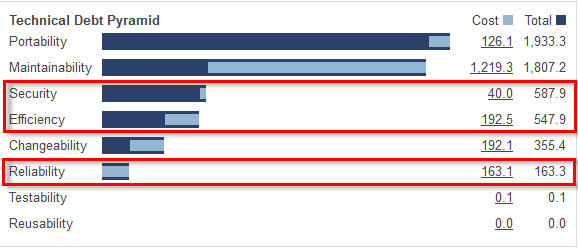
Un total de 395,6 días. Con 3 personas, esto es un trabajo de 7 meses
completos. Difícil de parar el proyecto durante más de la mitad del
año.
Sin embargo , estos 395 días incluyen los 113 del plan a corto plazo,
por lo que es en realidad un periodo adicional de 282 días, o 15 meses
de una persona o cinco meses para cada una de las tres personas del
equipo de el proyecto. Podemos pensar en varias sugerencias:
- Limitar el número de nuevas funcionalidades en las próximas cinco versiones para liberar un mes en cada versión para cada miembro del equipo y que se concentren en estas remediaciones. Es posible si esta aplicación ya no evoluciona demasiado y si los usuarios requieren mejoras en la fiabilidad y el rendimiento.
- Si muchas nuevas características son críticas y que la carga de cambio no se puede reducir, entonces los stakeholders deben estar dispuestos a pagar para agregar una cuarta persona en el equipo del proyecto, que se centrará exclusivamente en la corrección de estos defectos en las 5 próximas entregas.
Como se puede ver, este plan es en el horizonte de los próximos 18
meses, incluyendo el plan a corto plazo, pero es posible presentar
diferentes hipótesis, más aceptables para las partes interesadas y para
un Director de TI preocupado con su presupuesto. Una vez más, el plugin
SQALE permite que vayamos a lo esencial.
En el siguiente SQALE Sunburst, podemos ver que, en términos de
rendimiento (eficiencia ), se necesitan 104 días para corregir
violaciónes de una regla relativa a los tipos de datos.

Creo que es en la versión Oracle 11g que un nuevo tipo de datos ha
mejorado hasta en un 50% el rendimiento de algunos procedimientos
almacenados. Si el tiempo de respuesta de la aplicación no es un
problema importante para los usuarios, entonces podemos retrasar la
remediación de esta regla Major a más largo plazo y ganar 104 días o 21
semanas, alrededor de 7 semanas por cada miembro del equipo de proyecto.
Por supuesto, la idea no es de reducir el plan de mediano plazo a corto
plazo, sino concentrarse en lo esencial, con la ayuda de este gráfico
donde se muestra la distribución de la deuda técnica sobre diferentes
tipos de riesgos para la aplicación.
Plan a largo plazo – Alinear la deuda técnica con la estrategia de aplicación
El plan a largo plazo debe tratar de una pregunta obvia : ¿qué hacer con este componente monstruoso que
integra toda la lógica de negocio de la aplicación? El plugin SQALE
calcula que la deuda técnica para este componente es 1 431,9 días, el 75
% de la deuda técnica total para la aplicación (más de 6 años).
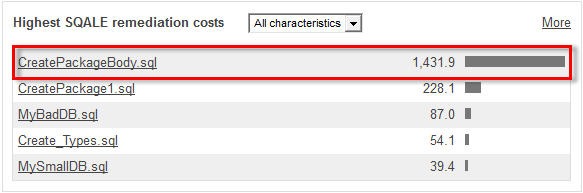
De hecho , la pregunta es ¿qué hacer con esta aplicación? Todo depende del nivel de criticidad.
Si una aplicación con una deuda técnica muy alta no es crítica, la
solución es simple: abandonala. Sigue a costar más mantenerla que
sustituirla, ya sea por un software o por una aplicación desarrollada en
una nueva tecnología más reciente. Debido a que la aplicación no es
crítica, no es esencial mantener el control o el conocimiento, por lo
que podemos, o bien externalizar este desarrollo a una empresa de
outsourcing, o realizar un RPF para poner en competición editores de
software e integradores. En todos los casos, el partner seleccionado
mantendrá la solución, normalmente con menor coste, pero con la
complejidad añadida de gestionar un proveedor externo.
Si la aplicación es crítica, entonces necesitarás manejar el problema
por tí mismo, ya que no quieres dejar a un tercero la gestión del
riesgo de negocio que esta aplicación puede representar para la empresa.
Hay entonces dos posibilidades: una refactorización de la aplicación o
una reescritura completa.
En este caso, corregir todos los defectos encontrados en este
componente monstruoso y dejarlo tal como es, eso no tiene mucho sentido.
La refactorización debe centrarse con prioridad en un nuevo diseño de
la aplicación, que en realidad promueve la solución de reescribirla con
una nueva tecnología.
Hemos visto que esta base de datos contiene 687 tablas, sin contar
las vistas, pero con una importante duplicación de estructuras de datos.
Mi recomendación para un plan a largo plazo será la siguiente:
- Llevar a cabo una retro-documentación para enumerar los diferentes componentes presentes en esta aplicación y los enlaces entre ellos.
- Para llevar a cabo un rediseño conceptual y una mapa de los objetos funcionales, inicialmente en el mismo perímetro, luego tomando en cuenta los cambios funcionales deseados por los usuarios.
Es posible subcontratar este trabajo a un proveedor de servicios,
sobre todo si el equipo de proyecto actual ha experimentado un turnover
importante durante la vida de esta aplicación y ha perdido un poco el
conocimiento de ella.
Sin embargo, este proveedor debe estar equipado con herramienta para
automatizar esta retro-documentación: 150.000 líneas de código y de
comentarios no es enorme, pero este trabajo no puede ser manual. Se
necesita una herramienta que permite rastrear todos componentes y sus
relaciones en una cartografía de la aplicación.
Pues esto es estupendo: SonarSource tiene previsto un proyecto para
una herramienta de este tipo. Nuestra aplicación PL/SQL será entonces un
buen candidato para una prueba de esta futura producción de
SonarSource.
Fuente:
http://qualilogy.com/es/analisis-plsql-con-sonarqube-evaluar-la-calidad-1/








No hay comentarios:
Publicar un comentario